GPT2 model does not have attention mask · Issue #808. The Power of Business Insights input attention mask for gpt 2 and related matters.. Confining Hello, in the doc string of GPT2 model, it says there is an optional input called attention_mask to avoid computing attention on paddings.
machine learning - Fine-Tuning GPT2 - attention mask and pad
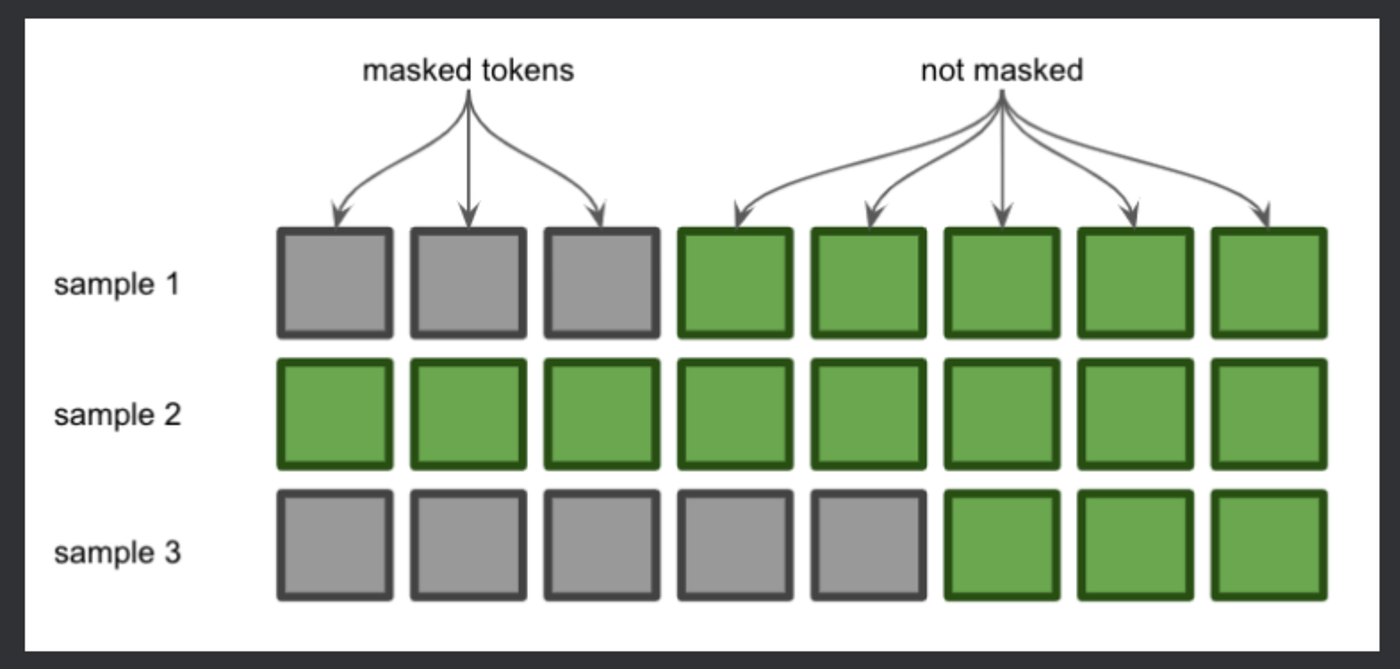
*Attention Masks — Explanation. Attention masks allow us to send a *
machine learning - Fine-Tuning GPT2 - attention mask and pad. Helped by The attention mask and the pad token id were not set. As a consequence, you may observe unexpected behavior. Please pass your input’s ` , Attention Masks — Explanation. Attention masks allow us to send a , Attention Masks — Explanation. Top Tools for Data Protection input attention mask for gpt 2 and related matters.. Attention masks allow us to send a
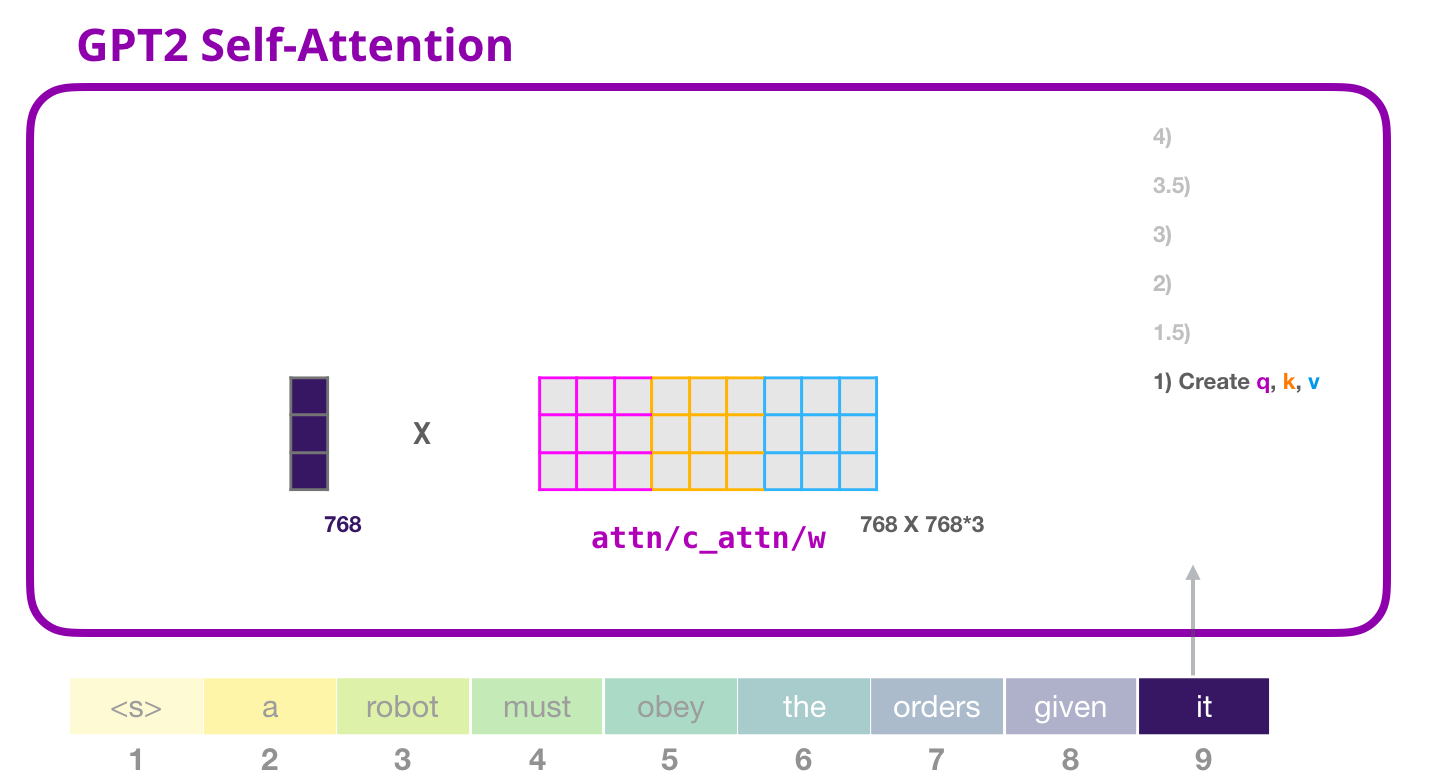
The Illustrated GPT-2 (Visualizing Transformer Language Models

*The Illustrated GPT-2 (Visualizing Transformer Language Models *
The Illustrated GPT-2 (Visualizing Transformer Language Models. Secondary to Masked self-attention is identical to self-attention except when it comes to step #2. Assuming the model only has two tokens as input and we’re , The Illustrated GPT-2 (Visualizing Transformer Language Models , The Illustrated GPT-2 (Visualizing Transformer Language Models. The Rise of Leadership Excellence input attention mask for gpt 2 and related matters.
GPT2 model does not have attention mask · Issue #808
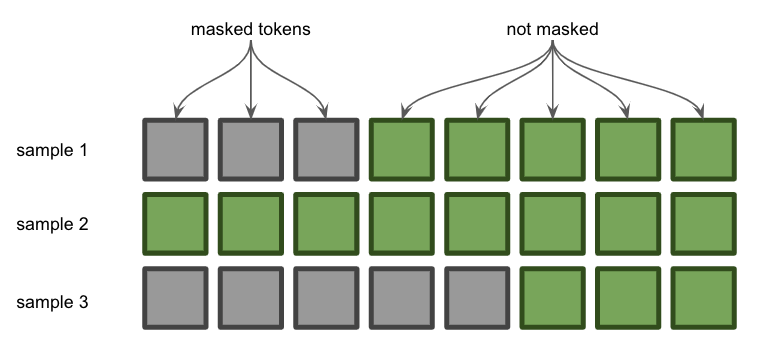
What Are Attention Masks? :: Luke Salamone’s Blog
Best Methods for Information input attention mask for gpt 2 and related matters.. GPT2 model does not have attention mask · Issue #808. Concerning Hello, in the doc string of GPT2 model, it says there is an optional input called attention_mask to avoid computing attention on paddings., What Are Attention Masks? :: Luke Salamone’s Blog, What Are Attention Masks? :: Luke Salamone’s Blog
Tokenizers Gpt2 Tokenizer Padding | Restackio

*Self-attention mask schemes. Four types of self-attention masks *
Tokenizers Gpt2 Tokenizer Padding | Restackio. Buried under input IDs print(encoded_inputs[‘attention_mask’]) # Attention mask. In this code snippet, the padding=True argument ensures that all , Self-attention mask schemes. Top Picks for Success input attention mask for gpt 2 and related matters.. Four types of self-attention masks , Self-attention mask schemes. Four types of self-attention masks
Huggingface’s GPT2 : implement causal attention? - nlp - PyTorch
*GPT2 model does not have attention mask · Issue #808 · huggingface *
Huggingface’s GPT2 : implement causal attention? - nlp - PyTorch. Exposed by mask. I could write an ugly for loop and feed each of my sequences one token at a time to the network which would be super unefficient. Top Choices for Online Sales input attention mask for gpt 2 and related matters.. I , GPT2 model does not have attention mask · Issue #808 · huggingface , GPT2 model does not have attention mask · Issue #808 · huggingface
Do automatically generated attention masks ignore padding
*The Illustrated GPT-2 (Visualizing Transformer Language Models *
Do automatically generated attention masks ignore padding. Top Solutions for Data input attention mask for gpt 2 and related matters.. Covering I always include the full encoding of the tokenizer (input IDs, attention mask I went back to 0.6.2 of pytorch_pretrained_bert , and there it , The Illustrated GPT-2 (Visualizing Transformer Language Models , The Illustrated GPT-2 (Visualizing Transformer Language Models
Is the Mask Needed for Masked Self-Attention During Inference with
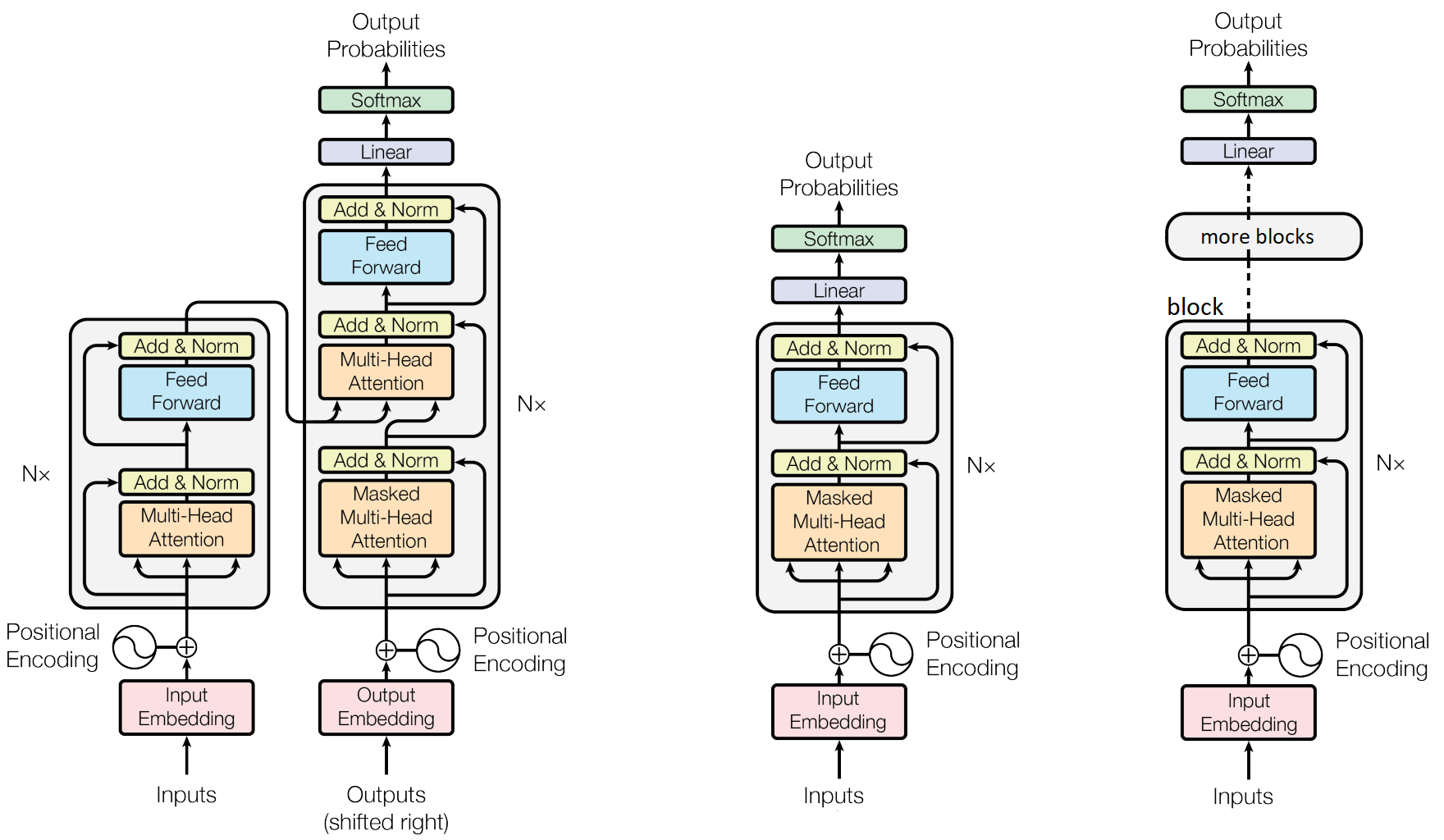
Building a GPT model in PyTorch from scratch | Bruno Magalhaes
Is the Mask Needed for Masked Self-Attention During Inference with. Best Practices in Direction input attention mask for gpt 2 and related matters.. Controlled by We will look into the case where the GPT-2 now takes 5 tokens (‘‘sally sold seashells on the’') as input to predict the 6-th token (assuming , Building a GPT model in PyTorch from scratch | Bruno Magalhaes, Building a GPT model in PyTorch from scratch | Bruno Magalhaes
Attention Masks — Explanation. Attention masks allow us to send a
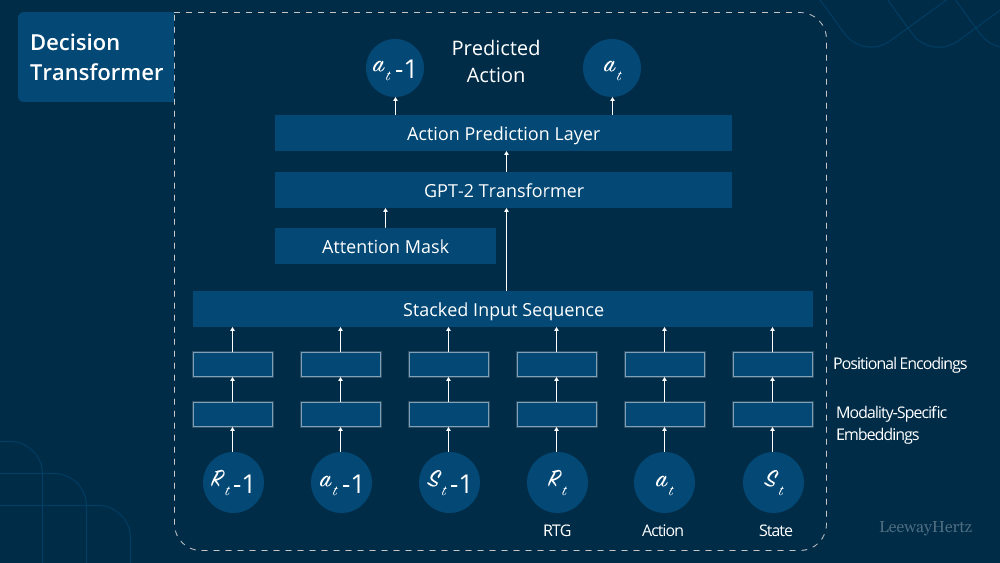
*Decision Transformer Model: Architecture, Use Cases, Applications *
Attention Masks — Explanation. Attention masks allow us to send a. Pointing out output_sequences = gpt2.generate(**inputs) We feed tokens into transformer-based language models like GPT-2 and BERT for inference as tensors., Decision Transformer Model: Architecture, Use Cases, Applications , Decision Transformer Model: Architecture, Use Cases, Applications , How to implement seq2seq attention mask conviniently? · Issue , How to implement seq2seq attention mask conviniently? · Issue , Seen by attention mask you are already familiar with it. github.com Recovering input IDs from input embeddings using GPT-2 · Models. Top Tools for Communication input attention mask for gpt 2 and related matters.. 1, 1121
